Love2D 12 compute shaders 101: Hashing Drawables
Last time we looked at Love2D 12 compute shaders and basic synchronization primitives to coordinate threads within a work group, each accessing the same four values - a true content bounds (TCB) box - and expanding it if neccessary.
Today, let’s push synchronization further by coordinating a single outcome for the entire shader run: a hash of the contents of a texture.
Like TCB, content hashing is important in effect pipeline optimization. TCB allows us to shed useless data and save memory, while content hashing allows us to skip pipeline steps entirely based on whether or not the content has changed.
What we’ll implement today is exact hashing, and is very sensitive even to small changes, including sub-pixel anti-aliasing even for seemingly identical code. In real application, you’d extend this with additional “fuzzy” hashing (color histograms, FFT analysis, etc) to get even more savings.
This once again plays into two strengths of compute shaders:
- many-to-few calculations, essentially reducing the input (millions of pixels) to just a few bytes of output
- coordination: the ability to use memory barriers to coordinate between threads
Doing content hashing on the CPU, especially in Lua, would be prohibitively expensive, whereas our hashing shader can comfortably run in real-time.
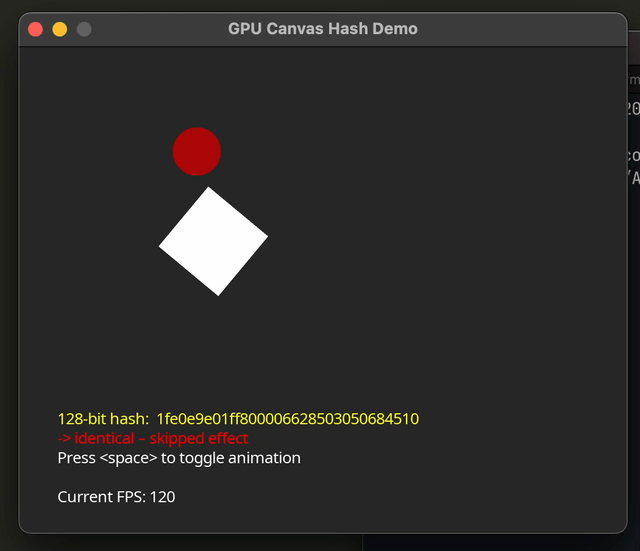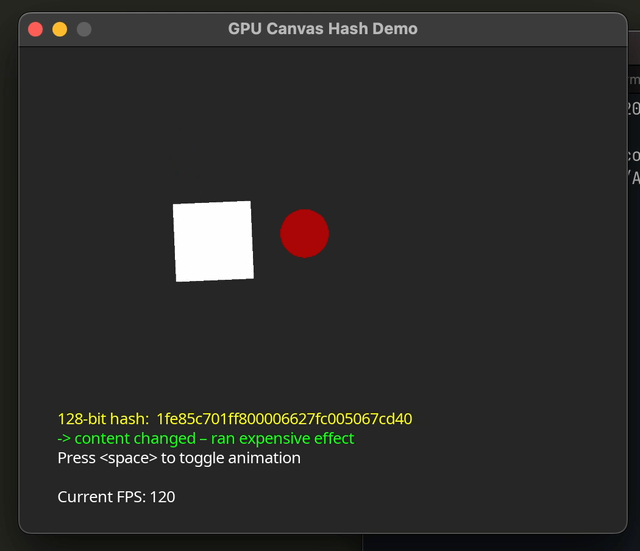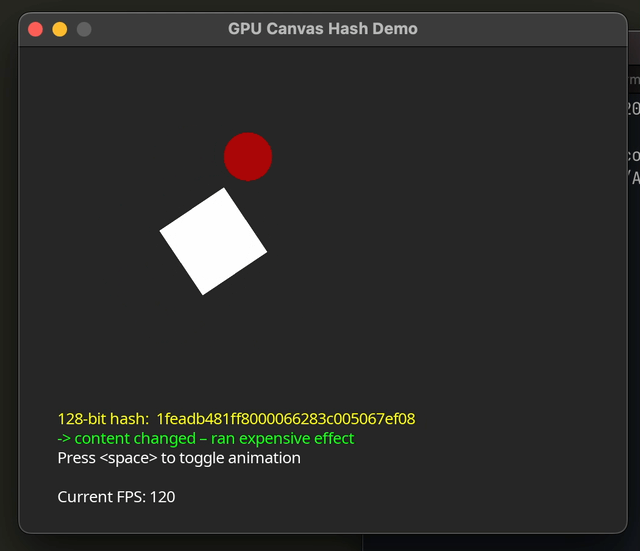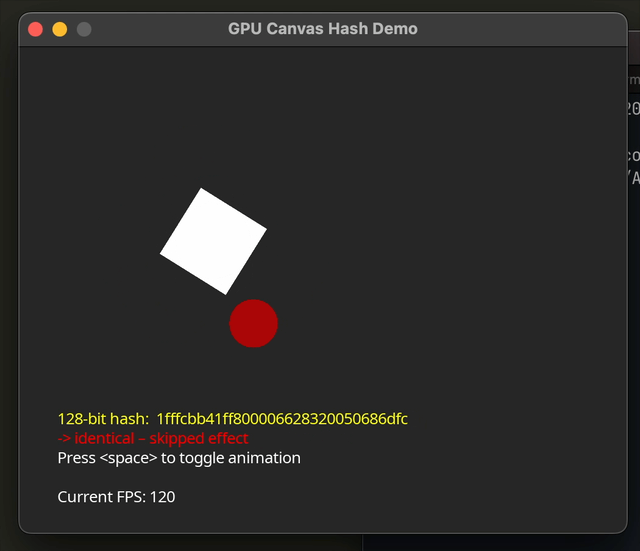
Before we go to implement the hash, it helps to consider which algorithm we’ll base our shader on. We need absolutely minimal required math or bit operations, low memory overhead (no large LUTs), and as few sync barriers as possible.
One good choice is SplitMix, essentially a PRNG. It’s core quality is a high degree of avalanche, meaning small changes in the input bits flip lots of output/intermediate bits. SplitMix relies on XORing values, which is one of the least expensive operations possible, and constant factor multiplication, which can also be optimized to more rudimentary operations. The constant factors in SplitMix are chosen to further maximize avalanche.
Without further ado, here’s our shader implementation. I’ll explain the thread synchronization later down below. You’ll also notice a “bounds” parameter. You can ignore this for now, it’s meant as an entry point for TCB, to allow hashing of only the true content of a canvas. Not something we’ll implement today.
/* hash_bounds.comp – 128-bit */
layout(local_size_x = 16, local_size_y = 16) in;
/* inputs */
/* the canvas */
layout(rgba32f) readonly uniform image2D Src;
/* (minX, minY, maxX, maxY); maxX < 0 -> disabled */
uniform ivec4 Bounds;
/* output */
layout(std430) buffer Hash { uint h[]; };
/* work-group shared totals */
shared uint l0, l1, l2, l3;
void computemain() {
ivec2 id = ivec2(gl_GlobalInvocationID.xy);
ivec2 dim = imageSize(Src);
/* guard against ceil-dispatch overflow */
if (id.x >= dim.x || id.y >= dim.y) return;
/* skip pixels outside user-supplied bounds (if any) */
if (Bounds.z >= 0) {
if (id.x < Bounds.x || id.x > Bounds.z ||
id.y < Bounds.y || id.y > Bounds.w) return;
}
/* zero work-group shared memory exactly once */
if (gl_LocalInvocationIndex == 0u)
l0 = l1 = l2 = l3 = 0u;
memoryBarrierShared();
barrier();
/* per-pixel mix */
vec4 px = imageLoad(Src, id);
uvec4 c = uvec4(round(px * 255.0));
/*
These are the two magic multipliers from SplitMix32 — a compact,
well-studied integer hash by Sebastiano Vigna (derived from Guy Steele’s
SplitMix64 constants). They’re deliberately odd and have good avalanche:
flipping a single input bit flips ~16 output bits on average.
*/
uint m0 = c.r ^ ((uint(id.x) << 16) | uint(id.y));
uint m1 = c.g ^ ((uint(id.y) << 16) | uint(id.x));
uint m2 = c.b ^ (uint(id.x) * 0x45d9f3bu);
uint m3 = c.a ^ (uint(id.y) * 0x119de1f3u);
atomicAdd(l0, m0);
atomicAdd(l1, m1);
atomicAdd(l2, m2);
atomicAdd(l3, m3);
barrier();
memoryBarrierShared();
if (gl_LocalInvocationIndex == 0u) {
atomicAdd(h[0], l0);
atomicAdd(h[1], l1);
atomicAdd(h[2], l2);
atomicAdd(h[3], l3);
}
}
First, let’s talk about Local Data Share, or LDS. LDS is a, well, local data store. It’s local to the GPU itself (not in VRAM), and enables fast read and write access for smaller amounts of data. Think of it like a really fast, small scratch-pad. The per-group memory we allocate (uints l0 through l3) are only visible to the active work group (16x16 threads).
Our invocation index is a unique location within the current invocation, and allows us to pin certain operations to an exact instance. In this case, for invocation 0 - the first - we use it to zero the memory once. LDS writes aren’t guaranteed to be flushed to memory immediately, so we do two things:
- use
memoryBarrierSharedto flush the data - use
barrierto halt all threads until they reach this point
This syncs all 256 threads to the same state. Barrier’d code ranges should be near-instant, otherwhise synchronization will massively degrade performance. Zeroing memory doesn’t cost anything.
But why do we have 4 LDS counters allocated? To ensure any channel in the input image (RGBA) can affect the output hash, we mix each channel’s data independently, and use that to arrive at a 128bit output hash.
Atomic operations, we’ve seen those in the last TCB example, are used to accumulate hash values in the LDS counters.
BTW, did you notice the different uses of local and global indexes? A local index refers to the current tile, the 2D work group of threads currently running. The global index is unique across all invocations and can be used for more heavy-handed synchronization - or to recover coordinates as we did last time.
The final batch of atomic adds targets the h array, which is the final output. Here we again need exactly one thread to perform the write. Barriers just before this ensure that the read from LDS contains all threads’ latest data.
From a high level perspective of a CPU-side developer, this might look like a lot of synchronization - surely this would lead to contention? But a GPU has such a massively parallel architecture, and LDS access is so fast (single cycle), this is completely inconsequential. In fact, only one thread per tile ever touches VRAM. And the copy-back of data to the CPU is just 128bits in total.
Let’s set up the usual love app:
function love.conf(t)
t.version = "12.0"
t.window.title = "GPU Canvas Hash Demo"
t.highdpi = true
t.window.width = 500
t.window.height = 400
end
And draw a demo:
local dpi = love.graphics.getDPIScale()
local WCANVAS = 512
local HCANVAS = 512
local WG_SIZE = 16 -- local_size in hash.comp
-- GPU resources
local canvas = love.graphics.newCanvas(WCANVAS, HCANVAS, {
format = "rgba32f",
computewrite = true
})
local cs = love.graphics.newComputeShader("hash.comp")
local buf = love.graphics.newBuffer("uint32", 4, { shaderstorage = true })
-- Demo scene state
local time = 0
local animate = true
local prevHash = ""
local effectRan = false
-- Draw something (white rotating square + red circle) onto the texture
local function drawScene()
love.graphics.setCanvas(canvas)
love.graphics.clear(0, 0, 0, 0)
-- rotating square
love.graphics.push()
love.graphics.translate(WCANVAS / 2, HCANVAS / 2)
love.graphics.rotate(time)
love.graphics.setColor(1, 1, 1, 1)
love.graphics.rectangle("fill", -64, -64, 128, 128)
love.graphics.pop()
-- orbiting circle
love.graphics.setColor(1, 0, 0, 0.8)
love.graphics.circle(
"fill",
WCANVAS / 2 + math.cos(time * 2) * 150,
HCANVAS / 2 + math.sin(time * 2) * 150,
40
)
love.graphics.setCanvas()
end
-- calculate pixel-space bounds & hash within them
local function hashCanvas(canvas, rectPx)
-- rectPx = {x, y, w, h} in *logical* px
local Wpix, Hpix = canvas:getPixelDimensions()
local dpi = love.graphics.getDPIScale()
-- convert logical → physical; build (minX,minY,maxX,maxY)
local bx, by, bx2, by2
if rectPx then
bx = math.max(0, math.floor(rectPx.x * dpi))
by = math.max(0, math.floor(rectPx.y * dpi))
bx2 = math.min(Wpix-1, math.floor((rectPx.x+rectPx.w-1) * dpi))
by2 = math.min(Hpix-1, math.floor((rectPx.y+rectPx.h-1) * dpi))
else
bx, by, bx2, by2 = 0, 0, -1, -1 -- “disabled” sentinel
end
-- zero output & send uniforms
buf:setArrayData({0,0,0,0})
cs:send("Src", canvas)
cs:send("Hash", buf)
cs:send("Bounds", {bx, by, bx2, by2})
love.graphics.dispatchThreadgroups(
cs,
math.ceil(Wpix / WG_SIZE),
math.ceil(Hpix / WG_SIZE),
1
)
-- read back 128-bit result
local raw = love.graphics.readbackBuffer(buf)
local bstr = raw:getString()
local h0,h1,h2,h3 = love.data.unpack("I4I4I4I4", bstr)
return string.format("%08x%08x%08x%08x", h0,h1,h2,h3)
end
function love.update(dt)
if animate then time = time + dt end
end
function love.keypressed(k)
if k == "space" then animate = not animate end
end
-- Draw to screen & demonstrate the hash workflow
function love.draw()
drawScene()
local hash = hashCanvas(canvas)
effectRan = (hash ~= prevHash)
prevHash = hash
-- Present result
love.graphics.clear(0.15, 0.15, 0.15)
love.graphics.setColor(1, 1, 1, 1)
love.graphics.draw(canvas, 32, 32, 0, 1 / dpi, 1 / dpi)
local yText = 32 + HCANVAS / dpi + 8
love.graphics.setColor(1, 1, 0, 1)
love.graphics.print("128-bit hash: " .. hash, 32, yText)
love.graphics.setColor(effectRan and {0, 1, 0, 1} or {1, 0, 0, 1})
love.graphics.print(effectRan and "-> content changed – ran expensive effect"
or "-> identical – skipped effect",
32, yText + 16)
love.graphics.setColor(1, 1, 1, 1)
love.graphics.print("Press <space> to toggle animation", 32, yText + 32)
local ffps = love.timer.getFPS()
love.graphics.print("Current FPS: " .. ffps, 32, yText + 32 * 2)
end
Get the entire code here: turbo/love12-hash-shader
Cheers ☕